
Utilización de sub-bloques dentro de un bloque
La utilización de bloques de gran tamaño no solo disminuyen la tasa de fallos sino que reduce el espacio de memoria caché dedicado al directorio (almacenamiento de las etiquetas de los bloques residentes en una línea). Sin embargo, bloques grandes aumentan la penalización por fallos debido al aumento de la cantidad de datos que se deben transferir en el servicio de cada fallo.
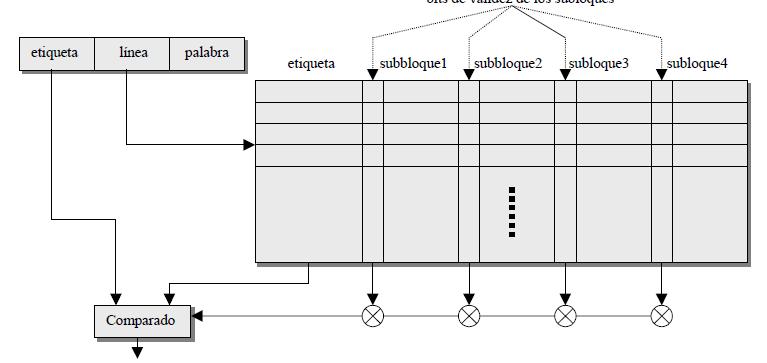
Una forma de disminuir la penalización por fallos sin modificar los otros factores positivos consiste en dividir el bloque en sub-bloques y asociar un bit de validez a cada sub-bloque. De esta forma, cuando se produzca un fallo, no será necesario actualizar más que el sub-bloque que contiene la palabra referenciada.
Esta alternativa hace que no sólo haya que comprobar si el bloque está en la caché comparando etiquetas, sino que habrá que asegurar que el sub-bloque que contiene la palabra referenciada es un sub-bloque válido, es decir, con datos actualizados.
También podemos ver esta alternativa de diseño como una forma de economizar información de directorio asociando una sola etiqueta a un grupo de bloques, e indicando con un bit particular asociado a cada bloque (bit de validez) su estado de actualización cuando el grupo está en Mc. En la siguiente figura se muestra un esquema de esta alternativa de diseño:
Fuente: Estructura de Computadores, Facultad de Informática, UCM