La E/S por interrupciones ocupa menos tiempo de CPU que la E/S controlada por programa. Sin embargo, con cualquiera de las dos alternativas las transferencias de datos deben pasar a través de la CPU. Esto significa que la velocidad de las transferencias está limitada por la velocidad a la que la CPU atiende el dispositivo periférico, ya que tiene que gestionarlas ejecutando una serie de instrucciones.
En la E/S controlada por programa la CPU está dedicada exclusivamente a la E/S, transfiriendo los datos a relativa velocidad, pero al precio de dedicarse a ello a tiempo completo.
Las interrupciones liberan en buena medida a la CPU de la gestión de las transferencias, a costa de disminuir su velocidad, pues la rutina de servicio de las interrupciones contiene por lo general instrucciones ajenas a la propia transferencia. Ambos procedimientos manifiestan, pues, ciertas limitaciones que afectan a la actividad de la CPU y la velocidad de transferencia.
Para poner de manifiesto de forma cuantitativa las limitaciones de la E/S programada y por interrupción, consideremos los dos siguientes supuestos:
Supuesto 1: conexión de un periférico lento, una impresora láser. La CPU opera a 200 Mhz. y su CPI vale 2. La impresora opera a 20 páginas/minuto, con 3.000 caracteres (bytes) por página. Se trata de imprimir un bloque de 10 Kbytes ubicado en la memoria.
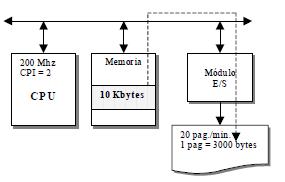
a) E/S programada
Una instrucción tarda en ejecutarse 2 * 5 ns = 10 ns, ya que el tiempo de ciclo Tc = 1/Frecuencia = 1/200*106 seg. = 1/200*106 * 10-9 ns = 5 ns.
La impresora imprime 20 * 3.000 = 60.000 caractéres/minuto = 1.000 caracteres/segundo = 1 Kbyte/s. Luego los 10 Kbytes los imprimirá en 10 segundos.
La CPU está ocupada durante 10 segundos
b) E/S por interrupción
Para este caso habrá que conocer el número de instrucciones que se ejecutan dentro de la rutina de tratamiento de la interrupción. Supondremos que son 10 las instrucciones (3 para salvar contexto, 2 para comprobar el estado y bifurcar, 1 para la transferencia, 3 para restaurar contexto, y 1 para retorno de interrupción, RTI). La impresora genera una interrupción cada vez que está preparada para recibir un nuevo caracter.
Para transferir los 10 Kbytes se producirán 10.000 interrupciones, lo que significa ejecutar 100.000 instrucciones.
Luego la CPU se ocupa durante 105 * 10 ns = 106 ns = 106 * 10-9 s. = 0,001 s. = 1 milisegundo.
La E/S por interrupción ha reducido en 10.000 veces el tiempo que la CPU está ocupada en atender la impresora. Sin embargo, la velocidad de la operación de E/S no ha cambiado, como era de esperar al estar dominada por la velocidad del periférico.
Supuesto 2: conexión de un periférico rápido, un disco magnético. La CPU opera igual que en caso anterior, es decir, a 200 Mhz y su CPI vale 2. El disco opera a una velocidad de transferencia de 10 Mbytes/s. Se trata en este caso de transmitir un bloque de 10 Mbytes de la memoria al disco.
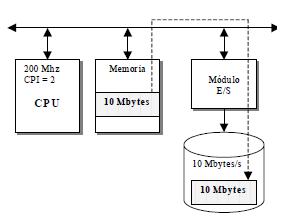
c) E/S programada
A la velocidad de 10 Mbytes/s el disco tarda 1 segundo en recibir los 10 Mbytes, y como
por E/S programada la CPU envia un byte cada vez que el disco está preparado para recibirlo, la CPU está ocupada en la tranferencia durante 1 segundo.
d) E/S por interrupción
Seguimos suponiendo que la rutina de tratamiento ejecuta 10 instrucciones. Como ahora se transmiten 107 bytes se producirán otras tantas interrupciones, lo que significa que la CPU ejecuta en toda la operación 107 * 10 = 108 instrucciones. Por tanto el tiempo total de ocupación de la CPU en la transferencia de E/S será 108 instrucciones * 10 ns/instrucción = 109 ns = 1 segundo.
Luego en el supuesto 2 las interrupciones no ahorran tiempo de CPU en la operación de E/S frente a la E/S programada. La razón está en que se ha llegado al límite de velocidad que es capáz de soportar la línea de interrupción del supuesto (1 byte cada 100 ns). Por encima de los 10 Mbytes/s la E/S por interrupción perdería datos puesto que se presentaría un nuevo byte antes de haber finalizado la rutina de tratamiento del byte anterior.
La E/S programada todavía admitiría mayor velocidad puesto que no tendría que ejecutar las instrucciones de guarda y restauración del contexto ni la instrucción RTI. El bucle de la E/S programada ejecutaría sólo 3 instrucciones (2 para comprobar el estado y bifurcar, 1 para la transferencia), es decir tardaría 30 ns en lugar de los 100 ns que tarda la rutina de tratamiento de la interrupción. Por tanto podría llegar hasta el límite de 30 ns/byte, es decir, 33 Mbytes/segundo
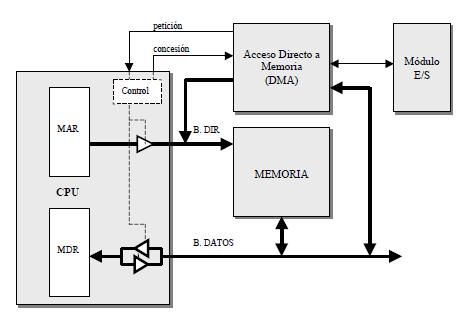
Por tanto, cuando se tienen que transferir grandes cantidades de datos y a una elevada velocidad, es necesario disponer de una técnica que realice de forma más directa las transferencias entre la memoria y el dispositivo periférico, limitando al máximo la intervención de la CPU. Esta técnica se conoce con el nombre de acceso directo a memoria (DMA: Direct Memory Access).
Básicamente se trata de un módulo con capacidad para leer/escribir directamente en la memoria los datos procedentes/enviados de/a los dispositivos periféricos. Para ello solicita la correspondiente petición a la CPU. Antes de que la CPU conceda acceso a memoria al DMA , pone en estado de alta impedancia su conexión a los buses del sistema (datos, direcciones y R/W), lo que es equivalente a desconectarse de la memoria durante el tiempo que es gestionada por el DMA.
Cuando finaliza la operación de E/S el DMA genera una interrupción y la CPU vuelve a tomar control de la memoria. De esta forma la velocidad de transferencia sólo estarán limitadas por el ancho de banda de la memoria.
Fuente: Estructura de Computadores, Facultad de Informática, UCM