Una lista doble , ó doblemente ligada es una colección de nodos en la cual cada nodo tiene dos punteros, uno de ellos apuntando a su predecesor (li) y otro a su sucesor(ld). Por medio de estos punteros se podrá avanzar o retroceder a través de la lista, según se tomen las direcciones de uno u otro puntero.
La estructura de un nodo en una lista doble es la siguiente:

Existen dos tipos de listas doblemente ligadas:
- Listas dobles lineales. En este tipo de lista doble, tanto el puntero izquierdo del primer nodo como el derecho del último nodo apuntan a NIL.
- Listas dobles circulares. En este tipo de lista doble, el puntero izquierdo del primer nodo apunta al último nodo de la lista, y el puntero derecho del último nodo apunta al primer nodo de la lista.
Debido a que las listas dobles circulares son más eficientes, los algoritmos que en esta sección se traten serán sobre listas dobles circulares.
En la figura siguiente se muestra un ejemplo de una lista doblemente ligada lineal que almacena números:
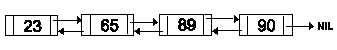
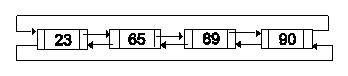
En la figura siguiente se muestra un ejemplo de una lista doblemente ligada circular que almacena números:
A continuación mostraremos algunos algoritmos sobre listas enlazadas. Como ya se mencionó, llamaremos li al puntero izquierdo y ld al puntero derecho, también usaremos el apuntador top para hacer referencia al primer nodo en la lista, y p para referenciar al nodo presente.
Algoritmo de creación
top<--NIL
repite
si top=NIL entonces
new(p)
lee(p(dato))
p(ld)<--p
p(li)<--p
top<--p
en caso contrario
new(p)
lee(p(dato))
p(ld)<--top
p(li)<--p
p(ld(li))<--p
mensaje(otro nodo?)
lee (respuesta)
hasta respuesta=no
Algoritmo para recorrer la lista
--RECORRIDO A LA DERECHA.
p<--top
repite
escribe(p(dato))
p<--p(ld)
hasta p=top
--RECORRIDO A LA IZQUIERDA.
p<--top
repite
escribe(p(dato))
p<--p(li)
hasta p=top(li)
Algoritmo para insertar antes de ‘X’ información
p<--top
mensaje (antes de ?)
lee(x)
repite
si p(dato)=x entonces
new(q)
leer(q(dato))
si p=top entonces
top<--q
q(ld)<--p
q(li)<--p(li)
p(ld(li))<--q
p(li)<--q
p<--top
en caso contrario
p<--p(ld)
hasta p=top
Algoritmo para insertar después de ‘X’ información
p<--top
mensaje(despues de ?)
lee(x)
repite
si p(dato)=x entonces
new(q)
lee(q(dato))
q(ld)<--p(ld)
q(li)<--p
p(li(ld))<--q
p(ld)<--q
p<--top
en caso contrario
p<--p(ld)
hasta p=top
Algoritmo para borrar un nodo
p<--top
mensaje(Valor a borrar)
lee(valor_a_borrar)
repite
si p(dato)=valor_a_borrar entonces
p(ld(li))<--p(ld)
p(li(ld))<--p(li)
si p=top entonces
si p(ld)=p(li) entonces
top<--nil
en caso contrario
top<--top(ld)
dispose(p)
p<--top
en caso contrario
p<--p(ld)
hasta p=top
Fuente: Apunte de Estructura de Datos del Instituto tecnológico de la Paz